#advanced dataframe features
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
DataFrame in Pandas: Guide to Creating Awesome DataFrames
Explore how to create a dataframe in Pandas, including data input methods, customization options, and practical examples.
Data analysis used to be a daunting task, reserved for statisticians and mathematicians. But with the rise of powerful tools like Python and its fantastic library, Pandas, anyone can become a data whiz! Pandas, in particular, shines with its DataFrames, these nifty tables that organize and manipulate data like magic. But where do you start? Fear not, fellow data enthusiast, for this guide will…
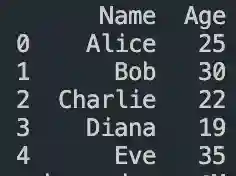
View On WordPress
#advanced dataframe features#aggregating data in pandas#create dataframe from dictionary in pandas#create dataframe from list in pandas#create dataframe in pandas#data manipulation in pandas#dataframe indexing#filter dataframe by condition#filter dataframe by multiple conditions#filtering data in pandas#grouping data in pandas#how to make a dataframe in pandas#manipulating data in pandas#merging dataframes#pandas data structures#pandas dataframe tutorial#python dataframe basics#rename columns in pandas dataframe#replace values in pandas dataframe#select columns in pandas dataframe#select rows in pandas dataframe#set column names in pandas dataframe#set row names in pandas dataframe
0 notes
Text
From List to Data: A Beginner’s Guide to Data Transformation
In today’s data-driven world, transforming raw information into structured formats is a critical skill. One common task in data processing is converting a list—a simple, unstructured sequence of values—into structured data that can be analyzed, visualized, or stored. A “list” might be a shopping list, a sequence of names, or numbers collected from user inputs. “Data,” in contrast, refers to a structured format such as a table, database, or dataset. The goal of transforming a list to data is to make it usable for insights, automation, or further manipulation. Understanding this process helps beginners make sense of how information is organized in software systems, spreadsheets, or databases. It’s not just a programming task—it’s a foundational part of digital literacy.
Why Converting Lists to Data Matters
Lists are everywhere: in text files, spreadsheets, form submissions, or even copied from emails. But these lists often need structure before they can be used. Structured data can be sorted, filtered, analyzed, or even turned into charts. For example, if you receive a list of customer names and purchases, it’s just raw text until it’s organized into phone number data and columns—where each row is a customer and each column is a data point like name, item, or price. Without this transformation, automation tools, machine learning models, or even basic Excel functions can’t work effectively. Converting lists to structured data enables better decisions, reporting, and scaling of workflows.

Simple Tools for List-to-Data Conversion
You don’t need to be a coder to transform lists into data. Tools like Microsoft Excel, Google Sheets, or Notepad++ make this easy. For example, using the "Text to Columns" feature in Excel, you can split list items into cells. In Google Sheets, functions like SPLIT() and ARRAYFORMULA() help break down and reorganize text. Online tools like CSV converters also turn lists into structured CSV files. These steps make it easier for users to handle raw data without complex scripts. Beginners can start with drag-and-drop interfaces and learn basic data formatting.
Moving Beyond Basics: Automation with Python and Scripts
Once you’re comfortable with basic tools, learning to automate list-to-data conversions with scripting languages like Python is a powerful next step. Python libraries such as pandas make it simple to import a list from a file and convert it into a DataFrame—a table-like data structure. For example, if you have a list stored in a .txt file, Python can read it, parse it using string functions, and format it into rows and columns automatically. This is especially useful when handling large or repetitive data. Automating the process not only saves time but also reduces human error. It opens the door to building entire data pipelines, integrating APIs, or performing advanced analysis.
0 notes
Text
Level Up Data Science Skills with Python: A Full Guide
Data science is one of the most in-demand careers in the world today, and Python is its go-to language. Whether you're just starting out or looking to sharpen your skills, mastering Python can open doors to countless opportunities in data analytics, machine learning, artificial intelligence, and beyond.
In this guide, we’ll explore how Python can take your data science abilities to the next level—covering core concepts, essential libraries, and practical tips for real-world application.
Why Python for Data Science?
Python’s popularity in data science is no accident. It’s beginner-friendly, versatile, and has a massive ecosystem of libraries and tools tailored specifically for data work. Here's why it stands out:
Clear syntax simplifies learning and ensures easier maintenance.
Community support means constant updates and rich documentation.
Powerful libraries for everything from data manipulation to visualization and machine learning.
Core Python Concepts Every Data Scientist Should Know
Establish a solid base by thoroughly understanding the basics before advancing to more complex methods:
Variables and Data Types: Get familiar with strings, integers, floats, lists, and dictionaries.
Control Flow: Master if-else conditions, for/while loops, and list comprehensions through practice.
Functions and Modules: Understand how to create reusable code by defining functions.
File Handling: Leverage built-in functions to handle reading from and writing to files.
Error Handling: Use try-except blocks to write robust programs.
Mastering these foundations ensures you can write clean, efficient code—critical for working with complex datasets.
Must-Know Python Libraries for Data Science
Once you're confident with Python basics, it’s time to explore the libraries that make data science truly powerful:
NumPy: For numerical operations and array manipulation. It forms the essential foundation for a wide range of data science libraries.
Pandas: Used for data cleaning, transformation, and analysis. DataFrames are essential for handling structured data.
Matplotlib & Seaborn: These libraries help visualize data. While Matplotlib gives you control, Seaborn makes it easier with beautiful default styles.
Scikit-learn: Perfect for building machine learning models. Features algorithms for tasks like classification, regression, clustering, and additional methods.
TensorFlow & PyTorch: For deep learning and neural networks. Choose one based on your project needs and personal preference.
Real-World Projects to Practice
Applying what you’ve learned through real-world projects is key to skill development. Here are a few ideas:
Data Cleaning Challenge: Work with messy datasets and clean them using Pandas.
Exploratory Data Analysis (EDA): Analyze a dataset, find patterns, and visualize results.
Build a Machine Learning Model: Use Scikit-learn to create a prediction model for housing prices, customer churn, or loan approval.
Sentiment Analysis: Use natural language processing (NLP) to analyze product reviews or tweets.
Completing these projects can enhance your portfolio and attract the attention of future employers.
Tips to Accelerate Your Learning
Join online courses and bootcamps: Join Online Platforms
Follow open-source projects on GitHub: Contribute to or learn from real codebases.
Engage with the community: Join forums like Stack Overflow or Reddit’s r/datascience.
Read documentation and blogs: Keep yourself informed about new features and optimal practices.
Set goals and stay consistent: Data science is a long-term journey, not a quick race.
Python is the cornerstone of modern data science. Whether you're manipulating data, building models, or visualizing insights, Python equips you with the tools to succeed. By mastering its fundamentals and exploring its powerful libraries, you can confidently tackle real-world data challenges and elevate your career in the process. If you're looking to sharpen your skills, enrolling in a Python course in Gurgaon can be a great way to get expert guidance and hands-on experience.
DataMites Institute stands out as a top international institute providing in-depth education in data science, AI, and machine learning. We provide expert-led courses designed for both beginners and professionals aiming to boost their careers.
Python vs R - What is the Difference, Pros and Cons
youtube
#python course#python training#python institute#learnpython#python#pythoncourseingurgaon#pythoncourseinindia#Youtube
0 notes
Text
Pandas DataFrame Cleanup: Master the Art of Dropping Columns Data cleaning and preprocessing are crucial steps in any data analysis project. When working with pandas DataFrames in Python, you'll often encounter situations where you need to remove unnecessary columns to streamline your dataset. In this comprehensive guide, we'll explore various methods to drop columns in pandas, complete with practical examples and best practices. Understanding the Basics of Column Dropping Before diving into the methods, let's understand why we might need to drop columns: Remove irrelevant features that don't contribute to analysis Eliminate duplicate or redundant information Clean up data before model training Reduce memory usage for large datasets Method 1: Using drop() - The Most Common Approach The drop() method is the most straightforward way to remove columns from a DataFrame. Here's how to use it: pythonCopyimport pandas as pd # Create a sample DataFrame df = pd.DataFrame( 'name': ['John', 'Alice', 'Bob'], 'age': [25, 30, 35], 'city': ['New York', 'London', 'Paris'], 'temp_col': [1, 2, 3] ) # Drop a single column df = df.drop('temp_col', axis=1) # Drop multiple columns df = df.drop(['city', 'age'], axis=1) The axis=1 parameter indicates we're dropping columns (not rows). Remember that drop() returns a new DataFrame by default, so we need to reassign it or use inplace=True. Method 2: Using del Statement - The Quick Solution For quick, permanent column removal, you can use Python's del statement: pythonCopy# Delete a column using del del df['temp_col'] Note that this method modifies the DataFrame directly and cannot be undone. Use it with caution! Method 3: Drop Columns Using pop() - Remove and Return The pop() method removes a column and returns it, which can be useful when you want to store the removed column: pythonCopy# Remove and store a column removed_column = df.pop('temp_col') Advanced Column Dropping Techniques Dropping Multiple Columns with Pattern Matching Sometimes you need to drop columns based on patterns in their names: pythonCopy# Drop columns that start with 'temp_' df = df.drop(columns=df.filter(regex='^temp_').columns) # Drop columns that contain certain text df = df.drop(columns=df.filter(like='unused').columns) Conditional Column Dropping You might want to drop columns based on certain conditions: pythonCopy# Drop columns with more than 50% missing values threshold = len(df) * 0.5 df = df.dropna(axis=1, thresh=threshold) # Drop columns of specific data types df = df.select_dtypes(exclude=['object']) Best Practices for Dropping Columns Make a Copy First pythonCopydf_clean = df.copy() df_clean = df_clean.drop('column_name', axis=1) Use Column Lists for Multiple Drops pythonCopycolumns_to_drop = ['col1', 'col2', 'col3'] df = df.drop(columns=columns_to_drop) Error Handling pythonCopytry: df = df.drop('non_existent_column', axis=1) except KeyError: print("Column not found in DataFrame") Performance Considerations When working with large datasets, consider these performance tips: Use inplace=True to avoid creating copies: pythonCopydf.drop('column_name', axis=1, inplace=True) Drop multiple columns at once rather than one by one: pythonCopy# More efficient df.drop(['col1', 'col2', 'col3'], axis=1, inplace=True) # Less efficient df.drop('col1', axis=1, inplace=True) df.drop('col2', axis=1, inplace=True) df.drop('col3', axis=1, inplace=True) Common Pitfalls and Solutions Dropping Non-existent Columns pythonCopy# Use errors='ignore' to skip non-existent columns df = df.drop('missing_column', axis=1, errors='ignore') Chain Operations Safely pythonCopy# Use method chaining carefully df = (df.drop('col1', axis=1) .drop('col2', axis=1) .reset_index(drop=True)) Real-World Applications Let's look at a practical example of cleaning a dataset: pythonCopy# Load a messy dataset df = pd.read_csv('raw_data.csv')
# Clean up the DataFrame df_clean = (df.drop(columns=['unnamed_column', 'duplicate_info']) # Remove unnecessary columns .drop(columns=df.filter(regex='^temp_').columns) # Remove temporary columns .drop(columns=df.columns[df.isna().sum() > len(df)*0.5]) # Remove columns with >50% missing values ) Integration with Data Science Workflows When preparing data for machine learning: pythonCopy# Drop target variable from features X = df.drop('target_variable', axis=1) y = df['target_variable'] # Drop non-numeric columns for certain algorithms X = X.select_dtypes(include=['float64', 'int64']) Conclusion Mastering column dropping in pandas is essential for effective data preprocessing. Whether you're using the simple drop() method or implementing more complex pattern-based dropping, understanding these techniques will make your data cleaning process more efficient and reliable. Remember to always consider your specific use case when choosing a method, and don't forget to make backups of important data before making permanent changes to your DataFrame. Now you're equipped with all the knowledge needed to effectively manage columns in your pandas DataFrames. Happy data cleaning!
0 notes
Text
Mastering Python: From Beginner to Pro in Data Science

Python has become the go-to language for data science, offering simplicity and powerful libraries. One of the key concepts in mastering Python is understanding overloading in Python, which can enhance the readability and functionality of your code.
Getting Started with Python
Before diving into data science, you need a solid foundation in Python. Start by setting up your environment using Anaconda or Jupyter Notebook. Learn the basics of Python syntax, data types, and structures, laying the groundwork for more advanced concepts.
Control Structures and Functions
Control structures allow you to dictate the flow of your program. Mastering loops and conditional statements is essential. Moreover, understanding functions, including the concept of overloading in Python, will enable you to create more versatile and reusable code.
Data Manipulation with Pandas
Pandas is the cornerstone of data manipulation in Python. You’ll work with DataFrames and Series to clean and preprocess your data. The ability to overload functions in Python can help you manage data operations more effectively, making your scripts more intuitive.
Data Visualization
Visualization is crucial for data analysis. Learn to create various plots using Matplotlib and Seaborn. Overloading can be used here to create functions that handle different types of data inputs, enabling you to streamline your visualization code.
Exploratory Data Analysis (EDA)
EDA involves summarizing and visualizing data to discover patterns. Use your knowledge of overloading in Python to write more dynamic functions that can handle different types of datasets, enhancing your analytical capabilities.
Introduction to Machine Learning
Get introduced to machine learning concepts, focusing on supervised and unsupervised learning. Use Scikit-learn to build models. Overloading can be particularly useful when developing multiple algorithms, allowing for flexible input parameters.
Advanced Data Science Techniques
Explore big data tools like Dask and delve into deep learning with TensorFlow. Overloading in Python can help you create flexible models that adapt to different input shapes and types.
Building a Data Science Project
Put your skills to the test by defining a data science project. Use overloading to manage various functions throughout your project, ensuring clarity and efficiency in your code.
Conclusion
Mastering Python for data science requires a comprehensive understanding of its features, including overloading. As you continue your journey, remember to leverage this powerful concept to write cleaner, more efficient code.
Read more : Python for Data Science and Analytics
0 notes
Text
Getting Started with Python’s Data Visualization Libraries
Data visualization is a vital component of data analysis, enabling us to present data insights in a clear and compelling way. As the world becomes increasingly data-driven, the ability to effectively visualize data is a sought-after skill. Python, with its rich ecosystem of libraries, has emerged as a powerful tool for data visualization. In this blog, we’ll explore some of the most popular Python libraries for data visualization and provide practical examples to get you started.
Why Data Visualization Matters
Data visualization transforms complex data into visual formats like charts and graphs, making it easier to understand and interpret. It allows analysts and decision-makers to spot trends, identify anomalies, and communicate findings effectively. For instance, a well-constructed line graph can reveal sales trends over time more intuitively than raw data in a spreadsheet.
Effective visualization not only enhances comprehension but also engages the audience. In a world inundated with data, the ability to distill and present information visually can differentiate impactful communication from overwhelming information.
Popular Python Data Visualization Libraries
Python boasts a variety of libraries tailored for data visualization. Here are some of the most widely used:
MatplotlibMatplotlib is the foundational library for creating static, animated, and interactive visualizations in Python. It is highly customizable, making it suitable for a wide range of applications.Installation:bashCopy codepip install matplotlib Basic Example:pythonCopy codeimport matplotlib.pyplot as plt x = [1, 2, 3, 4, 5] y = [2, 3, 5, 7, 11] plt.plot(x, y) plt.title('Simple Line Plot') plt.xlabel('X-axis') plt.ylabel('Y-axis') plt.show() This code snippet generates a simple line plot. You can easily customize the appearance by adding labels, titles, and styles.
SeabornBuilt on top of Matplotlib, Seaborn simplifies the creation of visually appealing statistical graphics. It offers built-in themes and color palettes for more attractive presentations.Installation:bashCopy codepip install seaborn Basic Example:pythonCopy codeimport seaborn as sns import matplotlib.pyplot as plt tips = sns.load_dataset('tips') sns.barplot(x='day', y='total_bill', data=tips) plt.title('Total Bill by Day') plt.show() In this example, we visualize the average total bill across different days using a bar plot. Seaborn also provides advanced features like categorical plots and pair plots for exploring relationships in data.
PlotlyFor interactive visualizations, Plotly is a fantastic choice. It allows users to create complex visualizations that can be embedded in web applications.Installation:bashCopy codepip install plotly Basic Example:pythonCopy codeimport plotly.express as px df = px.data.iris() fig = px.scatter(df, x='sepal_width', y='sepal_length', color='species') fig.show() This code creates an interactive scatter plot that displays different species of iris flowers based on their sepal dimensions. Users can hover over points for additional information, making it great for exploratory data analysis.
Pandas VisualizationWhile primarily a data manipulation library, Pandas has built-in capabilities for quick visualizations, allowing you to plot directly from DataFrames.Basic Example:pythonCopy codeimport pandas as pd import matplotlib.pyplot as plt data = {'Year': [2018, 2019, 2020, 2021], 'Sales': [150, 200, 250, 300]} df = pd.DataFrame(data) df.plot(x='Year', y='Sales', kind='line', title='Sales Over Years') plt.show() This approach offers a quick way to visualize data directly from your DataFrame, facilitating a seamless workflow from data analysis to visualization.
Getting Started with Basic Examples
To begin, it’s essential to install the necessary libraries. Use the following command to install all the libraries discussed:
bash
Copy code
pip install matplotlib seaborn plotly pandas
Now, let’s dive deeper into how to use these libraries effectively. For example, combining Matplotlib and Seaborn can enhance your visualizations:
python
Copy code
import seaborn as sns import matplotlib.pyplot as plt # Load the Titanic dataset titanic = sns.load_dataset('titanic') # Create a count plot of survivors sns.countplot(x='class', hue='survived', data=titanic) plt.title('Survivors by Class') plt.show()
This code creates a count plot showing the number of survivors by class on the Titanic, demonstrating how you can combine datasets and visualizations to glean insights.
"Take the First Step Towards Your Coding Career: join python training institute.
Advanced Visualization Techniques
Once you're comfortable with the basics, you can explore more advanced visualizations. Libraries like Bokeh and Altair provide functionalities for creating complex and interactive plots, such as time series analyses or geographical data representations.
Bokeh: Best for creating interactive plots that can be easily integrated into web applications.
Altair: Focused on declarative statistical visualizations, which make it easier to create complex plots with less code.
Best Practices in Data Visualization
To create effective visualizations, consider the following best practices:
Keep it Simple: Avoid clutter. Focus on the most important data points and minimize distractions.
Use Color Wisely: Choose a color palette that enhances readability and accessibility.
Label Clearly: Ensure all axes and legends are clearly labeled, providing context for your audience.
Tell a Story: Structure your visualizations to convey a narrative, guiding the audience through the data.
Conclusion
Mastering data visualization in Python is an invaluable skill that can significantly enhance your data analysis capabilities. By leveraging libraries like Matplotlib, Seaborn, Plotly, and Pandas, you can create compelling visual representations of data, making it easier to communicate insights and drive decision-making.
As you embark on your journey into data visualization, practice is key. Experiment with different libraries and visual styles, and always keep the principles of effective visualization in mind. With time and experience, you'll be able to craft stunning visual narratives that bring your data to life.
Call to Action
Ready to dive deeper into Python and data visualization? Join our upcoming courses at [Your Training Institute Name] to sharpen your skills and connect with like-minded learners. Let’s explore the fascinating world of data together!
DO YOU WANT TO LEARN PYTHON TRAINING COURSE WITH US?IF YES THEN MEET US IN PYTHON TRAINING INSTITUTE...
1 note
·
View note
Text
Python Programming Mastery for Aspiring Data Scientists: Essential Tools and Techniques
In the dynamic world of data science, Python has emerged as a powerhouse programming language. Its versatility and simplicity make it a go-to tool for data scientists, from beginners to seasoned professionals. If you're venturing into the realm of data science, mastering Python is a crucial step. In this guide, we'll explore the essential tools and techniques of Python programming tailored for aspiring data scientists.
1. Introduction to Python for Data Science
Python's popularity in data science stems from its readability and vast array of libraries tailored for data manipulation, analysis, and visualization. Unlike complex programming languages, Python's syntax is clear and concise, making it accessible for beginners. Whether you're handling large datasets or creating machine learning models, Python provides a robust foundation.
2. Setting Up Your Python Environment
Before diving into Python programming for data science, setting up your development environment is essential. You'll need to install Python and choose an Integrated Development Environment (IDE) such as PyCharm, Jupyter Notebook, or VS Code. These tools offer features like code autocompletion and debugging, streamlining your coding process.
3. Essential Python Libraries for Data Science
Python's strength lies in its libraries, which are pre-written pieces of code that simplify complex tasks. For data science, several libraries are indispensable:
NumPy: Known for its powerful array and matrix operations, NumPy is the foundation of many numerical computing tasks.
Pandas: Pandas excels in data manipulation and analysis, offering data structures like DataFrames for handling structured data.
Matplotlib and Seaborn: These libraries enable the creation of insightful visualizations, crucial for understanding data patterns and trends.
4. Data Cleaning and Preparation with Pandas
Before any analysis, data must undergo cleaning and preprocessing. Pandas' functionalities allow you to:
Remove duplicate entries
Handle missing values
Convert data types
Filter and sort data
By mastering these techniques, you ensure your data is ready for in-depth analysis and modeling.
5. Exploratory Data Analysis (EDA)
Exploratory Data Analysis is a fundamental step in understanding your dataset. With Python, you can:
Generate descriptive statistics
Create visualizations such as histograms, scatter plots, and box plots
Identify correlations between variables
EDA provides valuable insights into the underlying patterns of your data, guiding your subsequent analysis.
6. Machine Learning with Scikit-Learn
Python's Scikit-Learn library offers a comprehensive toolkit for machine learning tasks. Whether you're working on classification, regression, or clustering, Scikit-Learn provides:
Various algorithms, from linear regression to support vector machines
Tools for model evaluation, including metrics like accuracy, precision, and recall
Support for model selection and hyperparameter tuning
By leveraging Scikit-Learn, you can build predictive models to make data-driven decisions.
7. Advanced Techniques: Feature Engineering and Dimensionality Reduction
Feature engineering involves creating new features from existing data, enhancing a model's performance. Python libraries like Scikit-Learn and Feature-Engine offer methods for:
Handling categorical variables
Creating interaction terms
Scaling and normalizing features
Dimensionality reduction techniques, such as Principal Component Analysis (PCA), help manage high-dimensional data, improving model efficiency.
8. Deep Learning with TensorFlow and Keras
For complex tasks like image recognition and natural language processing, deep learning is indispensable. Python's TensorFlow and Keras libraries provide a user-friendly interface to:
Build neural networks with customizable layers
Train models on large datasets efficiently
Deploy models to production environments
Deep learning opens doors to cutting-edge applications in data science, pushing the boundaries of what's possible.
9. Putting It All Together: Real-World Projects
The best way to solidify your Python skills for data science is through hands-on projects. Consider projects such as:
Predicting housing prices based on historical data
Classifying spam emails using machine learning algorithms
Analyzing sentiment from social media posts
These projects not only enhance your programming abilities but also showcase your proficiency to potential employers.
Conclusion: Your Journey to Data Science Excellence
Mastering Python programming for data science is a rewarding journey. With the essential tools and techniques covered in this guide, you're equipped to tackle real-world challenges and unlock insights from data. Whether you're cleaning messy datasets, visualizing trends, or building sophisticated machine learning models, Python empowers you every step of the way. So, roll up your sleeves, dive into Python, and embark on your path to becoming an accomplished data scientist!
0 notes
Text
Top Data Science Tools Every Data Scientist Should Know
The field of data science is a rapidly evolving and dynamic domain that relies heavily on a diverse set of tools and technologies to gather, analyze, and interpret data effectively. Whether you are just starting your journey in data science or are looking to expand your toolkit, understanding the essential tools is crucial.

In this comprehensive guide, we will explore some of the top data science tools that every data scientist should consider using. These tools empower professionals to extract valuable insights from data, perform advanced analytics, and build intelligent solutions.
Python: The Versatile Powerhouse
Python is often considered the go-to programming language for data scientists. It has gained immense popularity due to its simplicity, readability, and a vast ecosystem of libraries and frameworks tailored for data science tasks. Some of the key Python libraries and frameworks that make it an essential tool for data scientists include:
NumPy: NumPy provides support for large, multi-dimensional arrays and matrices. It is crucial for scientific and mathematical computations.
pandas: pandas is a data manipulation library that simplifies data analysis tasks, offering data structures like DataFrames and Series.
Matplotlib: Matplotlib is a visualization library for creating static, animated, and interactive plots and charts.
scikit-learn: scikit-learn is a machine learning library that offers a wide range of tools for data modeling, classification, regression, clustering, and more. It is known for its simplicity and effectiveness.
Python's versatility extends to natural language processing (NLP), deep learning, and other advanced data science areas, thanks to libraries like TensorFlow, Keras, and PyTorch.
SQL: The Language of Databases
Structured Query Language (SQL) is the cornerstone of database management. Understanding SQL is vital for data scientists, as it enables them to work with relational databases effectively. SQL provides a standardized way to interact with databases, allowing data extraction, transformation, and analysis. Data scientists often use SQL to:
Retrieve data from databases.
Filter and clean data.
Aggregate and summarize data.
Join multiple tables.
Perform complex data transformations.
A strong grasp of SQL is essential for managing and extracting insights from large datasets stored in relational databases.
Tableau: Simplifying Data Visualization
Data visualization is a critical aspect of data science, as it enables data scientists to communicate their findings effectively. Tableau is a powerful data visualization tool that simplifies the creation of interactive and shareable dashboards. Key features of Tableau include:
Intuitive drag-and-drop interface for designing visualizations.
Support for various data sources, including databases, spreadsheets, and cloud services.
Options for creating interactive dashboards and stories.
Robust analytics and statistical capabilities.
Tableau makes it easier for data scientists to convey complex data insights to stakeholders, making it an indispensable tool for data visualization.
Power BI: Microsoft's Data Visualization Solution
Power BI is Microsoft's robust tool for data visualization and business intelligence. It connects to various data sources, including databases, cloud services, and spreadsheets, and offers an array of features such as:
Interactive and customizable dashboards.
Advanced data modeling and transformation capabilities.
Integration with Microsoft Excel and other Microsoft products.
Options for sharing and collaboration.
Power BI is particularly valuable for organizations using Microsoft's ecosystem and seeking comprehensive data analytics and visualization solutions.
Spark: Accelerating Data Processing
Apache Spark is a fast, in-memory data processing engine that has become a cornerstone in big data analytics. It works seamlessly with Hadoop and simplifies data processing and machine learning tasks. Some key features of Spark include:
In-memory data processing for high-speed analytics.
Support for various data sources, including HDFS, Apache Cassandra, and Amazon S3.
Libraries for machine learning (MLlib) and graph processing (GraphX).
Distributed computing capabilities.
Spark is a go-to tool for data scientists dealing with large datasets and complex data processing tasks, as it significantly improves performance and scalability.
TensorFlow: Leading the Deep Learning Revolution
Google's TensorFlow is an open-source machine learning framework that has played a pivotal role in the deep learning revolution. It provides a flexible and powerful platform for building neural networks and deep learning models. TensorFlow offers the following advantages:
Support for deep learning architectures, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Scalability for distributed training and deployment.
Integration with high-level APIs like Keras for ease of use.
A thriving community and ecosystem with a wealth of pre-trained models.
TensorFlow empowers data scientists to tackle complex tasks such as image recognition, natural language processing, and recommendation systems.
scikit-learn: The Swiss Army Knife of Machine Learning
scikit-learn is a versatile machine learning library for Python that provides straightforward and effective tools for data modeling and analysis. Data scientists commonly use scikit-learn for various tasks, including:
Classification and regression tasks.
Clustering and dimensionality reduction.
Model selection and evaluation.
Hyperparameter tuning and cross-validation.
With its easy-to-use interface and extensive documentation, scikit-learn is an essential tool for data scientists, both beginners and experts, for building and evaluating machine learning models.
Keras: Simplicity in Deep Learning
Keras is an open-source deep learning library that runs on top of TensorFlow and other deep learning backends. It is known for its ease of use and rapid prototyping capabilities. Key advantages of Keras include:
High-level, user-friendly API for building neural networks.
Flexibility to experiment with various architectures and models.
Seamless integration with TensorFlow for advanced deep learning tasks.
Keras is an ideal choice for data scientists looking to experiment with neural networks and deep learning without getting bogged down by low-level details.
PyTorch: Flexibility and Dynamic Computation
PyTorch is another deep learning library that has been gaining popularity rapidly, particularly in the research community. It offers dynamic computation graphs, making it flexible for various deep learning tasks. PyTorch's features include:
Dynamic computation for dynamic neural networks.
A strong focus on research and experimentation.
Community support and a growing ecosystem.
Integration with popular libraries like NumPy.
PyTorch appeals to data scientists and researchers who prefer dynamic computation graphs and a more Pythonic approach to deep learning.
SAS: Comprehensive Analytics Platform
SAS is a comprehensive analytics platform used in various industries for advanced statistical analysis and predictive modeling. It provides a range of tools and solutions for data management, analytics, and visualization. Some key features of SAS include:
Advanced statistical analysis capabilities.
Enterprise-level data integration and management.
Tools for business intelligence and reporting.
Support for machine learning and artificial intelligence.
SAS is a preferred choice for organizations that require robust analytics solutions and have a legacy in using SAS tools for data science.
In conclusion, the field of data science offers a plethora of tools and technologies to help data scientists extract meaningful insights from data, perform advanced analytics, and build intelligent solutions. The choice of tools depends on your specific needs and preferences, as well as the nature of your data science projects.
To excel in the dynamic field of data science, it is essential to stay updated with the latest tools and technologies and continuously expand your skill set. Consider exploring Data Science courses and training programs offered by ACTE Technologies to enhance your data science skills and keep up with industry trends. ACTE Technologies provides comprehensive courses and resources to empower data scientists and professionals with the knowledge they need to thrive in this exciting and rapidly evolving field. Whether you are a beginner or an experienced data scientist, ongoing learning and mastery of these essential tools are key to success in the world of data science.
0 notes
Text
Getting Started With R: A Comprehensive Guide To Data Science

Are you ready to dive into the exciting world of data science? Look no further, because we’ve got your back! Whether you’re a beginner or an experienced programmer, this comprehensive guide is here to help you get started with R, the language that has revolutionized the way we analyze and visualize data. From understanding the basics to mastering advanced techniques, join us on this journey as we unravel all the secrets that will make you a proficient data scientist. Get ready to unlock endless possibilities and take your analytical skills to new heights with our ultimate guide to getting started with R!
What is R?
R is a programming language and free software environment for statistical computing and graphics supported by the R Foundation for Statistical Computing. The R language is widely used among statisticians and data miners for developing statistical software and data analysis.
Why Use R for Data Science?
R is a powerful statistical programming language that is commonly used for data science. R has many features that make it well suited for data science, including its ability to handle large data sets, its wide variety of statistical and graphical methods, and its extensibility.
R is also a free and open source software, which makes it accessible to everyone. There is a large and active community of R users who contribute packages and help others with their code. This makes it easy to get started with R and to find help when you need it.
Getting Started with R: Installing and Configuring the Software
Installing and configuring R can be a bit daunting for newcomers, but this guide will walk you through the process step-by-step.
First, you’ll need to download and install R from the official website. Once it’s installed, open R and you’ll be greeted by the console. From here, you can type in commands and run them immediately.
Next, you’ll need to install some additional packages to get the most out of R. The easiest way to do this is through the “install.packages” command. For example, if you want to install the dplyr package, you would type:
install.packages(“dplyr”)
And then press enter. R will now download and install the package automatically. Repeat this process for any other packages you want to install.
You’ll need to configure your working directory. This is the folder where all your data files will be stored. To do this, use the “setwd” command followed by the path to your working directory:
setwd(“C:/Users/Your Name/Documents/R”)
Now that R is installed and configured, you’re ready to start using it for data science!
Data Manipulation in R: Working with Tables and Data Frames
In order to work with data in R, you need to understand how to manipulate data tables and data frames. Data manipulation is a process of changing the structure, organization, or values of data. In R, there are two main ways to manipulate data: using the built-in functions and using the dplyr package.
The built-in functions are powerful tools for manipulating dataframes. However, they can be difficult to use and require a lot of code. The dplyr package makes it much easier to manipulate dataframes by providing a set of simple functions that can be chained together.
Exploring Data with Visualizations in R
There are many ways to explore data with visualizations, but R offers some great options for those just getting started. The ggplot2 package is a popular choice for creating static visualizations, while the plotly and shiny packages offer interactive options.
No matter what kind of visualization you’re looking to create, R has you covered. In this guide, we’ll show you how to get started with data visualization in R so that you can start making informative and beautiful charts and graphs.
Using Statistics and Machine Learning in R
R is a powerful statistical programming language that is widely used by data scientists. Statisticians and data miners use R to perform statistical analysis, machine learning, and data visualization.
R can be used for a variety of purposes, including:
– Statistical analysis – Machine learning – Data visualization
Statistical analysis in R can be performed using a variety of methods, including linear regression, logistic regression, and decision trees. R also supports a wide range of machine learning algorithms, including support vector machines, neural networks, and random forests. Additionally, R’s rich set of packages allow users to create sophisticated visualizations of their data.
Creating Reproducible Reports with R Markdown
R Markdown is a great way to create reproducible reports. It allows you to embed R code in your document, which can be run to generate the output. You can also include LaTeX code to format your document. R Markdown is easy to use and it’s a great way to share your work with others.
Deploying Predictive Models to Production with Shiny
Predictive models are a powerful tool for understanding and improving business processes. When deployed to production, predictive models can provide real-time insights that can help organizations make better decisions.
Shiny is an open source R package that makes it easy to build interactive web applications for predictive modeling. With Shiny, you can deploy your predictive models to production with just a few lines of code.
In this guide, we’ll show you how to get started with Shiny and deploy your first predictive model to production. We’ll also provide some tips on how to improve the performance of your predictive models in production.
If you’re new to R, be sure to check out our comprehensive guide to data science with R.
Alternatives to R for Data Science
Just because R is a popular language for data science doesn’t mean it’s the only option. In fact, there are plenty of other languages that can be used for data science projects. Here are some alternatives to R that you may want to consider:
Python: Python is a versatile language that can be used for everything from web development to data science. It’s also relatively easy to learn, making it a good choice for those just getting started with coding.
Java: Java is another versatile language that can be used for a variety of purposes, including data science. However, it’s important to note that Java is a more complex language than Python, so it may take longer to learn.
SQL: SQL is a database query language specifically designed for working with large datasets. If your project involves a lot of data manipulation, SQL may be a good option for you.
There are many other languages that could be used for data science, but these are some of the most popular options. Ultimately, the best language to use will depend on the specific needs of your project.
Conclusion
After reading this guide, you should have a better understanding of the basics of working with data in R. You should also be able to start using R for your own data analysis projects.
If you’re just getting started with R, I recommend checking out some of the resources in the “Further Reading” section below. In particular, I recommend the following resources:
R for Data Science by Hadley Wickham and Garrett Grolemund – This book is a great introduction to data science using R. It covers the basics of working with data in R, including loading and cleaning data, exploratory data analysis, and creating visualizations.
Advanced R by Hadley Wickham – This book is a more advanced guide to working with data in R. It covers topics such as writing functions, advanced data manipulation, and working with large datasets.
1 note
·
View note
Text
Exploiting Apache Spark's Potential: Changing Enormous Information InvestigationPresentation
In the realm of huge information examination, Apache Flash has arisen as a distinct advantage. Spark is now the preferred framework for handling large-scale data processing tasks due to its lightning-fast processing and advanced analytics capabilities. In this blog, we'll talk about how Apache Spark has changed big data analytics and the amazing features and benefits it offers.
The Ecosystem of Spark:
Apache Flash is an open-source, dispersed figuring framework that gives a broad environment to enormous information handling. It provides a single platform for a variety of data processing tasks, including machine learning, graph processing, batch processing, and real-time streaming. Flash's adaptable design permits it to flawlessly coordinate with well known huge information innovations like Hadoop, Hive, and HBase, making it a flexible device for information specialists and information researchers.
Lightning-Quick Handling:
Spark's exceptional processing speed is one of the main reasons for its popularity. Flash use in-memory registering, empowering it to store information in Smash and perform calculations in-memory. When compared to conventional disk-based systems, this significantly reduces the disk I/O overhead, resulting in significantly quicker processing times. Flash's capacity to convey information and calculations across a group of machines likewise adds to its superior presentation abilities.
Distributed resilient datasets (RDDs):
RDDs are the principal information structure in Apache Flash. They are shortcoming open minded, unchanging assortments of items that can be handled in lined up across a bunch. Because they automatically handle data partitioning and fault tolerance, RDDs enable effective distributed processing. Complex data manipulations and aggregations are made possible by RDDs' support for a variety of transformations and actions.
DataFrames and Spark SQL:
A higher-level interface for working with structured and semi-structured data is provided by Spark SQL. It seamlessly integrates with Spark's RDDs and lets users query data using SQL syntax. DataFrames, which are a more effective and optimized approach to working with structured data, are also included in Spark SQL. DataFrames provide a user-friendly tabular structure and enable data manipulations that take full advantage of Spark's distributed processing capabilities.
AI with MLlib:
Flash's MLlib library works on the execution of adaptable AI calculations. MLlib gives a rich arrangement of AI calculations and utilities that can be consistently incorporated with Flash work processes. Its conveyed nature considers preparing models on enormous datasets, making it reasonable for dealing with huge information AI assignments. In addition, hyperparameter tuning, pipeline construction, and model persistence are all supported by MLlib.
Processing Streams Using Spark Streaming:
Flash Streaming empowers continuous information handling and investigation. It ingests information in little, miniature group spans, considering close to constant handling. Spark Streaming is able to deal with enormous streams of data and carry out intricate calculations in real time thanks to its integration with well-known messaging systems like Apache Kafka. This makes it ideal for applications like extortion location, log examination, and IoT information handling.
Capabilities for Spark's Graph Processing:
Flash's GraphX library gives a versatile system to chart handling and investigation. It permits clients to control and investigate huge scope chart information productively. GraphX is a useful tool for
applications like social network analysis, recommendation systems, and network topology analysis because it supports a wide range of graph algorithms.
Conclusion:
By providing a powerful, adaptable, and effective framework for processing and analyzing massive datasets, Apache Spark has revolutionized big data analytics. It is the preferred choice for both data engineers and data scientists due to its lightning-fast processing capabilities, extensive ecosystem, and support for various data processing tasks. Spark is poised to play a crucial role in the future of big data analytics by driving innovation and uncovering insights from massive datasets with continued development and adoption.
Find more information @ https://olete.in/?subid=165&subcat=Apache Spark
0 notes
Text
Why should you take the PG Diploma in Data Science using Python?
Believe it or not, the fastest-growing Python usage is for data science. Behind the massive fan following of the Python lies numerous conditions. Python is a very simple language to learn. While on the other hand, Data Science using Python is a nifty tool with a range of benefits. As it is open-source, Python's flexibility and continuous improvements with Data Science have become a genuinely resourceful option.
Other integrated languages, such as Java, can be utilized in this well-established system. It is extremely beneficial for your professional to pursue data science training and have a bright future full of possibilities. It is crucial to get in touch with the best data science training institute in Bangalore for ideal support from the industry trainer in every possible way. Cranes Varsity is the top data science using python training institute where you'll not only learn but explore and build a future that will take you high in life with promising job placements.

Why is Python for Data Science the best?
Data science using python is in high demand across the globe. There are a few grounds to support the statement that Data Science with Python is the best among all to choose as a great career option. There are notable advantages to learning this, which are all listed below;
1: Simplistic Approach :
Python is very popular as a programming language mainly due to its simplicity. The best features are inherited with easy readability, making it a friendly language for beginners or freshers. It is time savvy which allows straightaway to get into the research part without spending most of its time in documentation. It is extensively used in statistical analysis, text processing, data analysis, web development, and much more.
2: One library for every sort of need:
In Data Science using Python, the following is the most assorted library that makes it propelling to Data Science professionals. Python libraries include;
● NumPy is one of the most accessible libraries to find the use case in Data science.
● Pandas are built on the top of the NumPy.
● SciPy is the scientific equivalent of NumPy.
There are some more libraries like SymPy (statistical applications); Shogun, PyLearn2, and PyMC (machine learning); Bokeh, ggplot, Plotly, prettyplotlib, and seaborn (data visualization and plotting), and csvkit, PyTables, SQLite3 (data formatting and storage), to name a few.
3: It’s Multi-paradigm Approach
A great thing about Python is it's not limited to any programming language. The multi-paradigm feature makes it unique, which enables the support of functional, procedural, and objective-oriented programming & aspect-oriented programming style as well. With the data science certification, all this knowledge you'll gain eventually in training.
Who are all eligible for the data science online course?
Once you know about the immense benefits that you'll gather with the learning of Python in Data Science, you must be feeling to find out who is eligible for this? At Cranes Varsity, you can apply for the Data Science using Python training course if you are a working professional from an Engineering background, who is willing to increase your knowledge for better career aspects.
What is included in the data science training?
At Cranes Varsity, Data Science using Python training course syllabus is well-structured in terms of modules that will help the students better understand the subject. It includes:
● Relational Database - MySQL
● NoSQL - Mongo DB
● Web Technology - HTML, CSS, JavaScript
● Python Programming
● Advanced Python & Unit Testing
● Statistics
● Data Analysis & Visualization
● Machine Learning using SKlearn
● Deep Learning using Tenser Flow
● Tableau, Cloud Computing
You'll learn:
● Understand concepts like lambdas and CSV file manipulation.
● Describe standard Python data science functionality and features.
● For cleaning and processing, use DataFrame structures.
● Explain how t-tests, sampling, and distributions work.
About the PG Diploma in Data Science with Python at Cranes Varsity
The PG Diploma in Data Science using Python is a four-month professional program that provides solid knowledge and comprehension of Data Science. The expert teachers/ trainers have been industry leaders for decades. They offer instruction in all necessary disciplines so that engineers may create Java-based applications that satisfy industry standards.
As the best data science training institute in Bangalore, Cranes provides students with an organized framework to help them improve their technical skills and knowledge curve. The lectures are well-planned and delivered using examples to make them more engaging and understandable. The goal is to help students develop more strong knowledge representations in their heads in Data Science using Python.
Choosing Crane s Varsity is ideal for you in many ways:
● Extraordinary faculty who are practically experienced for years and know in and out of the market trends.
● Online and offline assistance from time to time.
● All notes are provided related to the Data Science using Python
● Guaranteed placement to the top companies in the country
● Extensive study and knowledge sharing sessions
● Open discussions are appreciated
● Full-time assistance 24/7 over time
● Timely assessment
How valuable is the data science certification?
Once you have chosen the data science online course from Cranes Varsity, there is no looking back. Your qualifications will be valued at the best ways to the top class management where you can explore more opportunities. The chances of placement are guaranteed from the Cranes campus for those who complete the training successfully. Data Science using Python training course is not just a course. It is a promising way to advance with the trend and demands of employment opportunities for the long run.
The platforms used in the Cranes Varsity for offering Data Science Using Python are;
● Anaconda Distribution (Jupyter Notebook)
● Tableau
● MYSQL
● Mongo DB
● Google Colab
● AWS
Any data science using python training institute won't offer such versatility in the module designing and syllabus that covers so much, apart from Cranes Varsity. The placement opportunities are on a larger scale to the top organizations in the country. Do not wait and skip your chance; apply/register for the course today! With this helpful data science using python certification, you'll surely see a better career for yourself.
0 notes
Text
100%OFF | Python 3 Data Science: NumPy, Pandas, and Time Series

Become a Master in Data Acquisition, Visualization, and Time Series Analysis with Python 3 and acquire employers’ one of the most requested skills of 21st Century! An expert level Data Science professional can earn minimum $100000 (that’s five zeros after 1) in today’s economy.
This is the most comprehensive, yet straight-forward course for the Data Science and Time Series with Python 3 on Udemy! Whether you have never worked with Data Science before, already know basics of Python, or want to learn the advanced features of Pandas Time Series with Python 3, this course is for you! In this course we will teach you Data Science and Time Series with Python 3, Jupyter, NumPy, Pandas, Matplotlib, and Plotly .
(Note, we also provide you PDFs and Jupyter Notebooks in case you need them)
With over 100 lectures and more than 13 hours of video this comprehensive course leaves no stone unturned in teaching you Data Science with Python 3, Pandas, and Time Series Analysis!
This course will teach you Data Science and Time Series in a very practical manner, with every lecture comes a programming video and a corresponding Jupyter notebook that has Python 3 code! Learn in whatever manner is the best for you!
We will start by helping you get Python3, NumPy, matplotlib, Jupyter, Pandas, and Plotly installed on your Windows computer and Raspberry Pi.
We cover a wide variety of topics, including:
Basics of Scientific Python Ecosystem
Basics of Pandas
Basics of NumPy and Matplotlib
Installation of Python 3 on Windows
Setting up Raspberry Pi
Tour of Python 3 environment on Raspberry Pi
Jupyter installation and basics
NumPy Ndarrays
Array Creation Routines
Basic Visualization with Matplotlib
Ndarray Manipulation
Random Array Generation
Bitwise Operations
Statistical Functions
Basics of Matplotlib
Installation of SciPy and Pandas
Linear Algebra with NumPy and SciPy
Data Acquisition with Python 3
MySQL and Python 3
Data Acquisition with Pandas
Dataframes and Series in Pandas
Time Series in Pandas
Time Series analysis with Matplotlib, Plotly, Seaborn, and Altair
You will get lifetime access to over 100 lectures plus corresponding PDFs and the Jupyter notebooks for the lectures!
So what are you waiting for? Learn Data Science and Time Series with Python 3 in a way that will advance your career and increase your knowledge, all in a fun and practical way!
Who this course is for:
Data Science Professionals: Data Scientists and Data Engineers
AI and Machine Learning Professionals
Scientists, Mathematicians, Physicists, and Engineers
Python Developers and Programmers
Managers and Business Professionals
Anyone who wants to learn
[ENROLL THE COURSE]
1 note
·
View note
Text
Excel Combining Training Data Science Course
Learn tips on how to load multiple sheets from an Excel document and the way to handle common errors encountered when reading CSV (comma-separated values) information. Explore joining tabular information by combining two associated knowledge sets through the use of a join operation, and spreading information—reshaping tabular information by spreading values from rows to columns. This course uses Python, the popular programming language for data science, to discover Pandas, a popular Python library, and is a part of the open-supply PyData stack. In this eleven-video Skillsoft Aspire course, learners will use Pandas DataFrame to carry out superior category grouping, aggregations, and filtering operations. You will see how to use Pandas to retrieve a subset of your knowledge by performing filtering operations both on rows, in addition to columns. You will perform analysis on multilevel knowledge through the use of the GROUP BY operation on the Dataframe. You will then study to use information masking or data obfuscation to protect classified or commercially sensitive information.
The function of a Data Analyst can differ relying on what kind of business they're in or which part of their group they are supporting. Data Analysts gather information, analyze that data and translate the results into insights to share with business stakeholders. Deep Learning Containers Containers with knowledge science frameworks, libraries, and instruments. Additionally, we've included a thorough Jupyter Notebook course, and a fast Python reference to refresh your programming abilities.
Due to the restricted area of this course, interested students ought to enroll as quickly as potential. Data mining is a powerful software used to find patterns and relationships in information. Learn the way to apply knowledge mining principles to the dissection of enormous advanced information sets, together with those in very large databases or through internet mining. Explore, analyze and leverage knowledge and switch it into priceless, actionable info on your firm. Demonstrate your abilities and experience by gaining the internationally recognized BCS Advanced International Diploma in Business Analysis, obtainable once you have accomplished three other skilled-degree modules. The course at Study Analytics was very interactive and covers all the essential needs that the company expects from Freshers.
Data Science Course
Learn steps involved in remodeling big information into smart data through the use of k-NN, and look at numerous sensible information resolution implementation frameworks. Recall how to turn good data into the business through the use of information sharing and algorithms and tips on how to implement clustering on smart data. Finally, find out about integrating sensible data and its impact on the optimization of data techniques. Discover the way to implement information pipelines utilizing Python Luigi, integrate Spark and Tableau to manage data pipelines, use Dask arrays, and construct data pipeline visualization with Python on this 10-video course. Begin by learning about features of Celery and Luigi that can be utilized to set up information pipelines, then how to implement Python Luigi to set up knowledge pipelines. Next, turn to work with the Dask library, after listing the essential options supplied by Dask from the perspective of task scheduling and massive information collections.
This Course Completion Certificate is Shareable to employers for better Career progress. Top Rated Data Science Courses to Become Machine Learning Scientist, Data Engineer, and Data analyst.
You can reach us at:
Name: ExcelR- Data Science, Data Analyst, Business Analyst Course Training in Delhi
Address: M 130-131, Inside ABL Work Space,Second Floor, Connaught CircleConnaught PlaceNew Delhi,110001. Phone: 09632156744.
Data Science Course
0 notes
Text
Python Data Science Essentials: Beginner's Guide to Analyzing Data
Introduction:
In today's data-driven world, the ability to analyze and interpret data is becoming increasingly valuable. Python, with its simplicity and versatility, has emerged as a powerful tool for data science. Whether you're a beginner or an experienced programmer, Python offers a wide range of libraries and tools tailored for data analysis. In this beginner's guide, we'll explore the essentials of using Python for data science, breaking down complex concepts into easy-to-understand language.
Why Python for Data Science?
Python has gained immense popularity in the field of data science due to several reasons. Its simple syntax makes it easy to learn for beginners, while its robust libraries offer advanced functionalities for data analysis. Additionally, Python enjoys strong community support, with a vast ecosystem of resources, tutorials, and forums available for assistance.
Setting Up Your Python Environment
Before diving into data analysis, you'll need to set up your Python environment. Start by installing Python from the official website (python.org) or using a distribution like Anaconda, which comes bundled with popular data science libraries such as NumPy, pandas, and Matplotlib. Once installed, you can use an integrated development environment (IDE) like Jupyter Notebook or Visual Studio Code for coding.
Understanding Data Structures in Python
Python offers various data structures that are essential for data manipulation and analysis. These include lists, tuples, dictionaries, and sets. Understanding how these data structures work will greatly enhance your ability to handle and process data effectively.
Introduction to NumPy and Pandas
NumPy and Pandas are two fundamental libraries for data manipulation in Python. NumPy provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays. Pandas, on the other hand, offers data structures like DataFrame and Series, which are ideal for handling structured data.
Data Visualization with Matplotlib and Seaborn
Visualizing data is crucial for gaining insights and communicating findings effectively. Matplotlib and Seaborn are popular Python libraries for creating static, interactive, and publication-quality visualizations. From simple line plots to complex heatmaps, these libraries offer a wide range of plotting functionalities.
Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) is the process of analyzing data sets to summarize their main characteristics, often employing visual methods. Python's libraries, such as Pandas and Matplotlib, facilitate EDA by providing tools for data manipulation and visualization. Through EDA, you can uncover patterns, detect anomalies, and formulate hypotheses about the underlying data.
Introduction to Machine Learning with Scikit-Learn
Machine learning is a subset of artificial intelligence that enables systems to learn from data without being explicitly programmed. Scikit-Learn is a powerful machine learning library in Python, offering a wide range of algorithms for classification, regression, clustering, and more. By leveraging Scikit-Learn, you can build predictive models and make data-driven decisions.
Data Cleaning and Preprocessing
Before applying machine learning algorithms to your data, it's essential to clean and preprocess it to ensure accuracy and reliability. Python provides tools for handling missing values, removing outliers, encoding categorical variables, and scaling features. By preprocessing your data effectively, you can improve the performance of your machine learning models.
Conclusion: Embracing Python for Data Science
In conclusion, Python serves as a versatile and accessible platform for data science, offering a rich ecosystem of libraries and tools for every stage of the data analysis pipeline. Whether you're exploring data, building predictive models, or visualizing insights, Python provides the necessary resources to unlock the potential of your data. By mastering the essentials outlined in this guide, you'll be well-equipped to embark on your journey into the fascinating world of data science.
In this article, we've covered the fundamental aspects of using Python for data science, from setting up your environment to performing exploratory data analysis and building machine learning models. With its user-friendly syntax and powerful libraries, Python empowers beginners and professionals alike to extract valuable insights from data and drive informed decision-making. So, whether you're a curious enthusiast or a seasoned data scientist, Python is your gateway to the exciting field of data science.
0 notes
Text
Introductory To Knowledge Analysis Using Excel

After numerous hours and sessions of research and learning, we’ve narrowed down the record of one of the best Data Analytics coaching and online programs excellent for novices, intermediates and specialists alike. This list contains both free and paid online programs that will help you study data evaluation. In this information, we’ll present you what one of the best data analytics courses with certificates to study knowledge analysis are, and how one can get a few of these knowledge analytics training classes at no cost or for less.
If you are looking to improve your excel expertise THIS is the company you should invest your time in.
Excel, however most individuals don’t know fairly how advanced spreadsheet evaluation can get.
You'll additionally study how to identify the computing requirements appropriate for fixing those issues.
Initially, you'll study some foundational ideas, together with primary calculations such as imply, median, and commonplace deviation, and provides an introduction to the central limit theorem.
Start by learning key information analysis tools such as Microsoft Excel, Python, SQL and R.
On some stage, every business relies on information science in one way or one other. That’s why plenty of firms rent information analysts and knowledge scientists interchangeably. Smaller organizations often mix the role; which means knowledge analysts have to have a good suggestion of knowledge sciences. Data analysts gather, consider, and analyze raw knowledge to help corporations in their decision-making process. Ideally, information analysts gather data from a quantity of sources, together with direct and oblique sources, and carry out thorough information evaluation to communicate the relevant findings instantly or via well-designed stories. When you buy the course, you get free entry to their Data Fundamentals Handbook that features all the content of the course in written form.
Chance And Statistics In Information Science Using Python
Alison provides dozens of excessive quality knowledge science courses designed by specialists and universities to provide you with an interactive and enriched learning expertise. When joining any of those courses you want to make the same commitment to learning as you'll in the course of a school course. One goal for studying data science online is to maximize psychological discomfort. It’s easy to get caught in the behavior of signing in to look at a few videos and really feel like you’re learning, but you’re not likely studying much until it hurts your mind.
You will use Python's DataFrame a two-dimensional size-mutable, potentially heterogeneous tabular information structure with labeled axes . To take this course, you must already be familiar with Python programming language; all code writing is in Jupyter notebooks. You will work with fundamental Pandas knowledge constructions, Pandas Series objects representing a single column of information which can retailer numerical values, strings, Booleans, and extra advanced knowledge varieties. Learn the means to use Pandas DataFrame, which represents data in table type. Finally, be taught to append and kind collection values, add lacking information, add columns, and combination information in a DataFrame. In this Skillsoft Aspire course, learners will encounter primary Hadoop file system operations similar to viewing the contents of directories and creating new ones. [newline]Begin by working with recordsdata in various ways, including transferring recordsdata between a local file system and HDFS and discover ways to create and delete information on HDFS.
What is the difference between data analytics and data analysis?
Data analysis refers to the process of examining, transforming and arranging a given data set in specific ways in order to study its individual parts and extract useful information. Data analytics is an overarching science or discipline that encompasses the complete management of data.
Every yr, 10 students will get suggestions on their project from information scientists working at Airbnb. At the tip of the course, college students complete a Capstone Project designed in conjunction with Yahoo. The entire Specialization takes about forty hours to complete, which means that students can finish the program in simply six months in the occasion that they spend three hours a week studying.
College Students Rated Our Data Analytics Lessons
Finally, observe how to create and analyze categories of information in a knowledge set by utilizing Windows. Extracting meaningful info from a really massive dataset could be painstaking. In this Skillsoft Aspire course, learners examine how Hadoop's MapReduce can be utilized to hurry up this operation.
Is data Analytics a stressful job?
Data analysis is a stressful job. Although there are multiple reasons, high on the list is the large volume of work, tight deadlines, and work requests from multiple sources and management levels.
New options, particular provides, and exciting information about the world of information visualization. Python is a high-level, dynamically typed, and transportable programming language that excels when the value of software development outweighs performance concerns. Data governance is an built-in framework of insurance policies and technology applied to ensure effective knowledge administration.
Unit 1: Introduction To Python
These sources embrace each free and paid ones created by top professionals, schools and corporations. There are 4 programs in the program – Foundations of strategic enterprise analytics, Foundations of promoting analytics, Case studies in enterprise analytics with Accenture and Capstone Project. Learners need to finish all the 4 programs to earn MicroMasters program certificates from ColumbiaX.
youtube
0 notes
Text
Data analyst course in Delhi

Learn tips on how to load multiple sheets from an Excel document and the way to handle common errors encountered when reading CSV (comma-separated values) information. Explore joining tabular information by combining two associated knowledge sets through the use of a join operation, and spreading information—reshaping tabular information by spreading values from rows to columns. This course uses Python, the popular programming language for data science, to discover Pandas, a popular Python library, and is a part of the open-supply PyData stack. In this eleven-video Skillsoft Aspire course, learners will use Pandas DataFrame to carry out superior category grouping, aggregations, and filtering operations. You will see how to use Pandas to retrieve a subset of your knowledge by performing filtering operations both on rows, in addition to columns. You will perform analysis on multilevel knowledge through the use of the GROUP BY operation on the Dataframe. You will then study to use information masking or data obfuscation to protect classified or commercially sensitive information.
The function of a Data Analyst course in Delhi can differ relying on what kind of business they're in or which part of their group they are supporting. Data Analysts gather information, analyze that data and translate the results into insights to share with business stakeholders. Deep Learning Containers Containers with knowledge science frameworks, libraries, and instruments. Additionally, we've included a thorough Jupyter Notebook course, and a fast Python reference to refresh your programming abilities.
Due to the restricted area on this course, interested students ought to enroll as quickly as potential. Data mining is a powerful software used to find patterns and relationships in information. Learn the way to apply knowledge mining principles to the dissection of enormous advanced information sets, together with those in very large databases or through internet mining. Explore, analyze and leverage knowledge and switch it into priceless, actionable info on your firm. Demonstrate your abilities and experience by gaining the internationally-recognized BCS Advanced International Diploma in Business Analysis, obtainable once you have accomplished three other skilled-degree modules. The course at Study Analytics was very interactive and covers all the essential needs that the company expects from Freshers.
Learn steps involved in remodeling big information into smart data through the use of k-NN, and look at numerous sensible information resolution implementation frameworks. Recall how to turn good data into a business through the use of information sharing and algorithms and tips on how to implement clustering on smart data. Finally, find out about integrating sensible data and its impact on optimization of data technique. Discover the way to implement information pipelines utilizing Python Luigi, integrate Spark and Tableau to manage data pipelines, use Dask arrays, and construct data pipeline visualization with Python on this 10-video course. Begin by learning about features of Celery and Luigi that can be utilized to set up information pipelines, then how to implement Python Luigi to set up knowledge pipelines. Next, turn to work with the Dask library, after listing the essential options supplied by Dask from the perspective of task scheduling and massive information collections.
This Course Completion Certificate is Shareable to employers for better Career progress. Top Rated Data Science Courses to Become Machine Learning Scientist, Data Engineer, and Data analyst course in Delhi.
Excel is the most extensively used spreadsheet program and is excellent for information analysis and visualization. Enroll in one of many free Excel programs and learn how to use this highly effective software.
Prepare for an entry-degree data scientist position with the IBM Data Science Professional Certificate. Augment human intelligence with machine insights at speed and scale, driving better buyer experiences.
Transfer Appliance Storage server for moving large volumes of information to Google Cloud. Cloud Data Transfer Tools and services for transferring your knowledge to Google Cloud. Cloud IoT Core IoT gadget administration, integration, and connection service.
We are dedicated to helping you find an approach to price range for this program and supply a variety of financing choices to make it extra economical. Attend a web-based interactive masterclass and get insights about advancements in technology/methods in Data Science, AI, and Machine Learning. Capstone from 3 domains and 14+ Projects with Industry datasets from Google PlayStore, Lyft, World Bank, and so on. Our career counselor will inform you quickly relating to the check particulars. The nature of the work of a Data Analyst means it’s almost at all times a requirement you've tertiary education in a related discipline. Along with the proper degree, there are different methods to set yourself aside in the industry. The demand for competent Data Analyst course in Delhi is mirrored by the excessive salaries provide for senior positions.
Learners will create an array and discover some of the fundamental operations, mostly mathematical ones, which can be performed on NumPy arrays. Next, study to change NumPy arrays, after which study more advanced operations, similar to indexing and slicing, common capabilities, and reshaping arrays. You will study universal features, which are NumPy library features, which function on a component-by-component foundation on NumPy arrays. Finally, you will discover various options which are available, to iterate by way of arrays in NumPy. As we reach the top of our knowledge evaluation journey, we go away with a small summary of the main methods and methods to perform wonderful analysis and develop your small business. At ExcelR, the Data Analyst course in Delhi curriculum provides extensive knowledge of Data Collection, Extraction, Cleansing, Exploration, and Transformation with expert trainers having 10+ years of experience with 100% placement assistance.
You can reach us at
:Address M 130-131, Inside ABL WorkSpace, Second Floor, Connaught Cir, Connaught Place, New Delhi, Delhi 110001
Phone 919632156744
Map Url https://g.page/ExcelRDataScienceDelhi?share
Base page link https://www.excelr.com/data-science-course-training
Web site Url https://www.excelr.com/data-science-course-training-in-delhi
0 notes